At present
SNPedia contains 1475 snps. The bulk of these are recent arrivals mined from
OMIM and
GeneRIF. But it all started with about 200 hand curated from pubmed searches, journals and news articles. These older snp pages tend to have accumulated the most information. Newer ones sorely need that sort of attention.
I foresee 2 audiences who can be served by SNPedia. The first audience is researchers who are actively trying to determine the effects of genomic variations. Often they've come here after googling for an rs#. For these people SNPedia may be a useful wiki portal to primary sources, a collective lab notebook, and a chat room. Linking to your own papers is
welcome.
The second audience is people who know aspects of their own genome. A very public example is Jim Watson, who recently released his genome. Craig Venter's genome should be public 'any day now', and Esther Dyson seems to want to be next. Given the numerous
testing options, it is safe to assume that there are others who already know aspects of their genome. More public and private genomes will surely follow.
But what does it mean to know some or all of your genome? Jim Waston was given a 'fasta' formatted text file.
It looked sort of like this:
>WATSON chromosome 1GTACGTATGCATGTTGGTGTGCAATATATTATGGCTGAGAGTCAGTCAGTCGATCTGACGTATGCTAGCAGTCTACGTAGCTAGCTAGCATGCTACGATGCGGGGAGCATATTGATCTGATCGATCGTAGATCGATGCAGCTACGAT...Except it has a an extra 6 billion As, Ts, Cs, and Gs. Its too big to fit on a DVD, and it doesn't come with a manual. How can you begin make sense of all that? Lincoln Stein at CSHL put together this
viewer. Thats a good start, but it's specific to Watson, and designed for asking particular questions.
SNPedia = SNP + wikipedia
Technically, a SNP is a Single Nucleotide Polymorphism. It means that a position in the dna was changed. I (ab)use the term 'snp' to mean a 'Small' Nucleotide Polymorphism. This encompasses changing a few neighboring letters, or inserting or deleting a few extras. If a snp changed the A at position 7 into a T the previous example would now look like this:
>WATSON chromosome 1 with an A>T snp at position 7GTACGTTTGC...>WATSON chromosome 1 with an AA insertion at position 7GTACGTAAATGC...The NCBI has been cataloging all of these snps in dbSNP. It's a great resource, and most importantly it is assigning a unique, stable and consistent name to each snp. These names look like
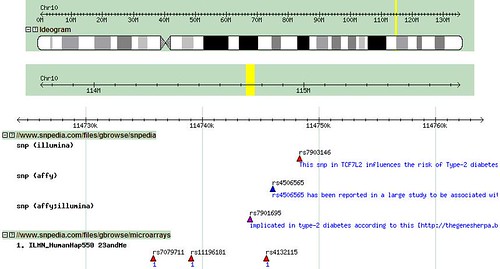
rs7903146. That is the letters 'rs' followed by a some digits. The snp is defined by having a certain pattern of letters 'upstream' of the change, a small variant, and a fixed 'downstream'.
Let's make this a bit more concrete. While the site always feels a bit slow for me,
http://www.ensembl.org/Homo_sapiens/snpview?source=dbSNP;snp=rs7903146
if you start at ensembl you can see the actual pattern of DNA for this snp.
In the field 'Flanking sequence' you will see a large chunk of dna, with a single red letter Y in the middle. A bit above that we are told
C/T (ambiguity code: Y)
Ancestral allele: T
We get two copies of dna -- one from mom, one from dad. All distant ancestors had this pattern of DNA with the T in the middle of both copies. A child was born with a mutation which changed it from a T to a C. This child lived to pass it on and it has continued to pass on for many generations.
Depending on which you got from each parent, at rs7903146 your dna is one of these 3 genotypes. (C;C) or (C;T) or (T;T).
Over at the NCBI page, you can see some primary data about the frequency of each of these in different populations.
http://www.ncbi.nlm.nih.gov/SNP/snp_ref.cgi?rs=7903146#Diversity
Among Chinese and Japanese, 95% of the people were (C;C). But among a Utah population of mixed european ancestry 33% were (C;T). And 8.3% were (T;T).
James Watson turns out to be a (C;T) as well.
http://jimwatsonsequence.cshl.edu/cgi-perl/gbrowse/jwsequence/?name=SNP%3Ars7903146
I'm currently in a bidding war with Science vs Nature for my paper proving that James Watson is not asian.
Surely google knows all.
http://www.google.com/search?hl=en&q=rs7903146
As I write this the top hit is a recent paper reporting "TCF7L2 rs7903146 variant does not associate with smallness for gestational age in the French population". Is that really the most important thing about this snp?
Google's second hit is on SNPedia
http://www.snpedia.com/index.php?title=Rs7903146
All of the links we've visited are already there on in the box on the right hand side. A simple explanation of the effect of this snp is in the main window, with hyperlinked citations to back it all up. There is even a box explaining the consequences for each genotype.
James Watson is at a moderately increased risk of Type-2 Diabetes due to his rs7903146(C;T) genotype.
Interestingly, the SNPedia page and the research papers present the (C;C) genotype as normal risk, while the (T;T) is greatly increased risk. However we've already seen that T is ancestral. So it seems more natural to view (T;T) and a high risk of diabetes as the historic and natural state. Jim has one copy of a more recent mutation which is reducing the risk.
So maybe it is more accurate to say
James Watson is at a moderately decreased risk of Type-2 Diabetes due to his rs7903146(C;T) genotype.
Its all depends on whether you compare him to rs7903146(C;C) or rs7903146(T;T). And there are other snps which further increase and decrease his risk. There is still a lot to learn.
If you're curious, try a few
random pages
http://www.snpedia.com/index.php?title=Special:Random
but before you leave the current page, click on TCF7L2
http://www.snpedia.com/index.php?title=TCF7L2
Its got one of those boxes at the right. Some of it is kind of useful, especially the 'mentioned by' link. This can find related snps automatically. But the TCF7L2 page is still pretty much a mess.
The pages about genes are bad.
The pages about diseases are worse.
This is not diseasapedia (although I do enjoy saying that)
This is SNPedia!

{kind=link}